Understanding fastai's Midlevel API
How to customize your data processing. Exploring Transforms, Pipelines, TfmdLists, Datasets


Even after going through the course and book, I didn't feel comfortable with the numerous classes and methods that fastai offers for data processing. I felt that it would be easy once I understood it, but it just didn't click right away. So here I try to present the most important classes and why they are useful.
This is by no means a complete overview, but just an exploration with minimal examples.
For a deeper dive, please check out chapter 11 of fastbook, Wayde Gilliam's awesome blog post, or Zach Mueller's walk with fastai2.
In general, our data is always in tuples of (input,target), although you can have more than one input or one target. When applying a transform, it should be applied to the elements of the tuple separately.
![]()
When you only want to implement the encoding behaviour of a transform, it can be defined via the @Transform decorator:
@Transform
def lowercase(x:str):
return str.lower(x)
lowercase("Hello, Dear Reader")
Type dispatch
Transforms can be defined so they apply only to certain types. This concept is called type dispatch and is provided by fastcore, which I'll cover in a future post :-)
@Transform
def square(x:int):
return x**2
square((3, 3.))
Notice the type annotation for x. In this case, this is not merely a helpful annotation like in pure Python, but it actually changes the behaviour of the function! The square transform is only applied to elements of the type int. When we don't define the type, a transform is applied on all types.
A more complex transform
If you want to also define the setup and decode methods, you can inherit from Transform:
class DumbTokenizer(Transform):
def setups(self, items):
vocab = set([char for text in items for char in text])
self.c2i = {char: i for i, char in enumerate(vocab)}
self.i2c = {i: char for i, char in enumerate(vocab)}
def encodes(self, x):
return [self.c2i.get(char, 999) for char in x]
def decodes(self, x):
return ''.join([self.i2c.get(n, ' ? ') for n in x])
texts = ["Hello", "Bonjour", "Guten Tag", "Konnichiwa"]
tokenizer = DumbTokenizer()
tokenizer.setup(texts)
encoded = tokenizer("Hello!")
encoded
Now this is a representation that a machine learning model can work with. But we humans can't read it anymore. To display the data and be able to analyze it, call decode on the result:
tokenizer.decode(encoded)
So here we defined a (very dumb) tokenizer. The setups method receives a bunch of items that we pass in. It creates a vocabulary of all characters that appear in items. In encodes we transform each character to a number in an index. When the character is not found in the vocabulary, it is replaced with a 999 token. decodes reverses this transform as good as it can.
Notice the ? in the decoded representation instead of !. Since there was no ! in the initial texts, the tokenizer replaced it with the token for "unkown", 999. This is then replaced with ? during decoding.
By the way: you might have noticed that in the DumbTokenizer class we defined the methods setups, encodes and decodes, but on the instance tokenizer we call methods with slightly different names (setup, decode) or even the instance directly: tokenizer(...). The reason for this is that fastai applies some magic in the background, for example it checks that the type is not changed by the transforms.

tfms = Pipeline([lowercase, tokenizer])
encoded = tfms("Hello World!")
encoded
Pipeline also supports decoding of an item:
tfms.decode(encoded)
Because we didn't define a decodes method for lowercase, this transform cannot be reversed. The decoded result consists only of lowercase letters.
What Pipeline doesn't provide is support for the setup of the transforms. When you want to apply a pipeline of transforms on a list of data, TfmdLists comes to the rescue.
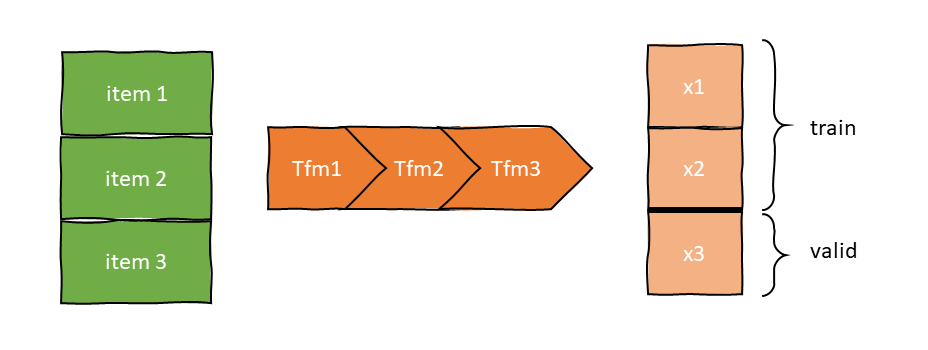
texts = ["Hello", "Bonjour", "Guten Tag", "Konnichiwa"]
tls = TfmdLists(texts, [DumbTokenizer])
When initialized, TfmdLists will call the setup method of each Transform in order, providing it with all the items of the previous Transform. To get the result of the pipeline on any raw element, just index into the TfmdLists:
encoded = tls[1]
encoded
tls.decode(encoded)
Training and validation sets
The reason that TfmdLists is named with an s (lists in plural) is that it can handle a training and a validation set. Use the splits argument to pass
- the indices of the elements that should be in the training set
- the indices of the elements that should be in the validation set.
We will just do this by hand in our toy example. The training set will be "Hello" and "Guten Tag", the other two go in the validation set.
texts = ["Hello", "Bonjour", "Guten Tag", "Konnichiwa"]
splits = [[0,2],[1,3]]
tls = TfmdLists(texts, [lowercase, DumbTokenizer], splits=splits)
We can then access the sets through the train and valid attributes:
encoded = tls.train[1]
encoded, tls.decode(encoded)
Let's look at at word in the validation set:
encoded = tls.valid[0]
encoded, tls.decode(encoded)
Ouch, what happened to our "Bonjour" here? When TfmdLists automatically called the setup method of the transforms, it only used the items of the training set. Since there was no b, j or r in our training data, the tokenizer treats them as unknown characters.
setup methods of the transforms receive only the items of the training set.
Don't we need labels?
Maybe you noticed that we haven't dealt with tuples until now. We only have transformed our input, we don't have a target yet.
TfmdLists is useful when you built a custom Transform that performs data preprocessing and returns tuples of inputs and targets. You can apply further transforms if you want, and then create a DataLoaders object with the dataloaders method.
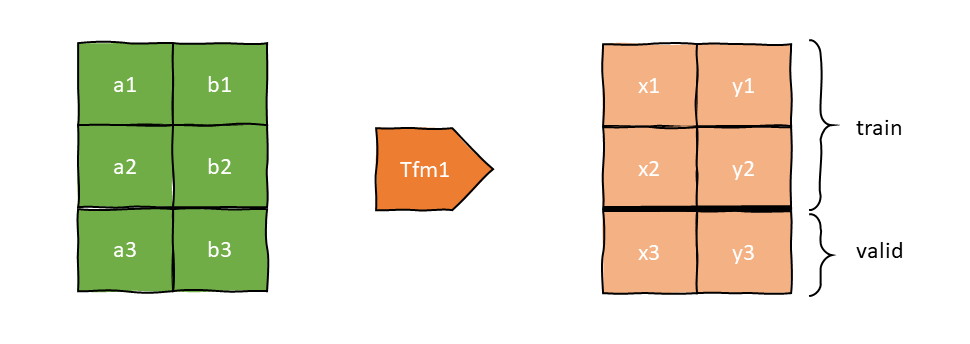
Usually however, you will have two parallel pipelines of transforms - one to convert your raw items to inputs, and one to convert raw items to targets (ie labels). To do this we can use Datasets.
Datasets
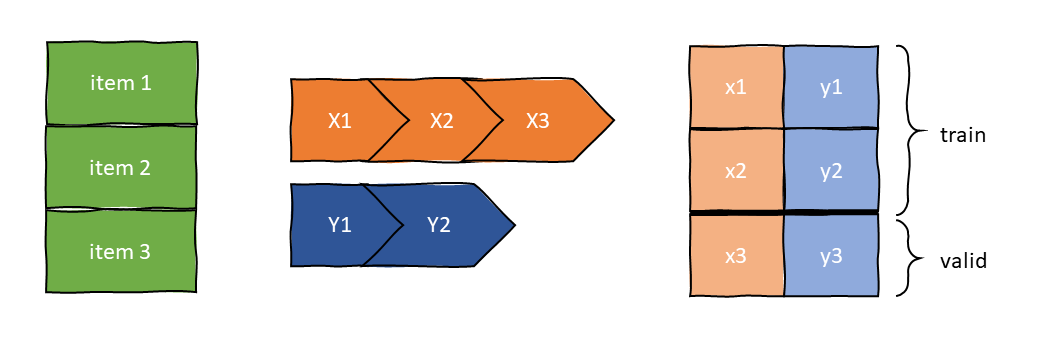
To complete our quick tour through fastai's midlevel API, we look at the Datasets class. It applies two (or more) pipelines in parallel to a list of raw items and builds tuples of the results. It performs very much like a TfmdLists object, in that it
- automatically does the setup of all Transforms
- supports training and validation sets
- supports indexing
The main difference is: When we index into it, it returns a tuple with the results of each pipeline.
Let's look at how to use it. For this toy example, let's pretend we want to classify whether a text contains at least one space (that's a dumb example, I know). For this we create a little labelling function in the form of a Transform.
class SpaceLabeller(Transform):
def encodes(self, x): return int(' ' in x)
def decodes(self, x): return bool(x)
x_tfms = [lowercase, DumbTokenizer]
y_tfms = [SpaceLabeller]
dsets = Datasets(texts, [x_tfms, y_tfms], splits=splits)
item = dsets.valid[1]
item
dsets.decode(item)
At last, we can create a DataLoaders object from the Datasets. To enable processing on the GPU, two small tweaks are required. First, every item has to be converted to a tensor (often this will happen earlier, as one of the transforms in the pipeline). Second, we use a fastai function called pad_input to make every sequence the same length, since a tensor requires regular shape.
dls = dsets.dataloaders(bs=1, after_item=tensor, before_batch=pad_input)
dls.train_ds
This is now a ready-for-training dataloader!
Conclusion
We looked at how to customize every step of the data transformation pipeline. As mentioned in the beginning, this is not a complete description of all the features available, but a good starting point for experimentation. I hope this was helpful to you, let me know if you have questions or suggestions for improvement at hannes@deeplearning.berlin or @daflowjoe on Twitter.